在前篇我們透過PaddleOCR,初步將建築圖紙上的文字資訊辨識成文字資料,接下來本篇將聚焦於常見的識別情境與誤判分析。唯有深入理解各類誤判背後的結構與成因,才能進一步用pandas將「資料」結構化為真正可用的「資訊」,為後續自動化建模的應用鋪路。
根據上一篇的操作步驟,模型所辨識的結果便能以(.txt)、(.png)方式將資料儲存,以利後續資料分析之用,範例如下圖13.1 & 圖13.2所示: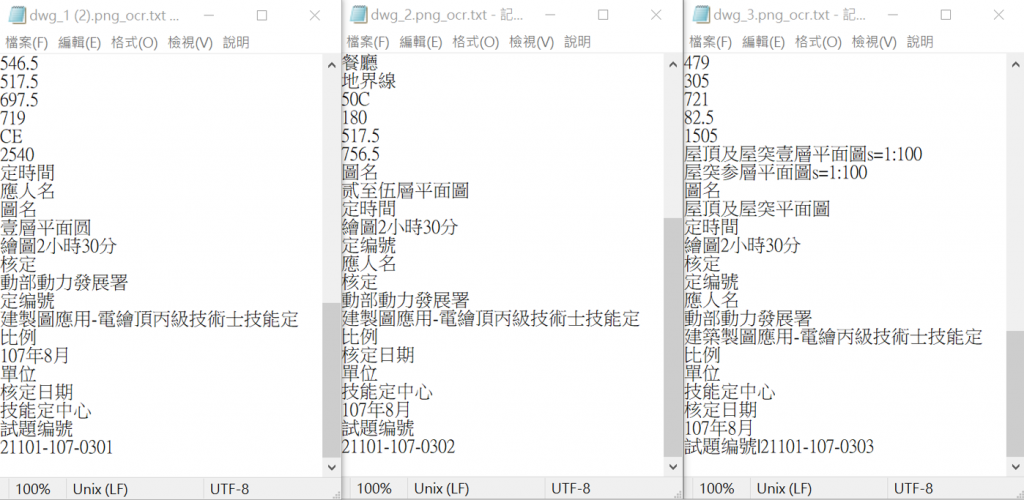
圖13.1 文字辨識結果文字檔
圖13.2 文字辨識結果可視圖
在檢視辨識結果之前,我們先來了解建築圖面中一般會有哪些文字資訊:
有了大致的資訊框架後,我們可以試著在Colab新增筆記本,並以pandas來整理辨識結果(Pandas 是 Python 最常用的資料分析工具,可讓你像處理 Excel 表格一樣,快速進行資料整理、篩選、統計與分析):
Step1:安裝pandas。
# 1. 安裝pandas
!pip install pandas
Step2:上傳txt檔案到Colab。
# 2. 上傳txt檔案到Colab
from google.colab import files
import pandas as pd
uploaded = files.upload()
# 檔名清單
filenames = list(uploaded.keys())
print("已上傳檔案:", filenames)
Step3:讀取並重新分類排序(中文、英文、數字、其他)。
# 3. 讀取並重新分類排序(中文、英文、數字、其他)
import re
import pandas as pd
df_dict = {} # 保留每個檔案處理結果
def classify_text(s):
s = str(s).strip()
if re.fullmatch(r'\d+(\.\d+)?', s):
return '數字'
elif re.fullmatch(r'[A-Za-z]+', s):
return '英文'
elif re.search(r'[\u4e00-\u9fff]', s):
return '中文'
else:
return '其他'
for fname in filenames:
with open(fname, encoding='utf-8') as f:
lines = [line.strip() for line in f if line.strip()]
df = pd.DataFrame({'text': lines})
df['分類'] = df['text'].apply(classify_text)
# 改成你要的順序
sort_order = ['中文', '英文', '數字', '其他']
df['排序索引'] = df['分類'].map(lambda x: sort_order.index(x) if x in sort_order else len(sort_order))
df_sorted = df.sort_values(by=['排序索引', 'text'], ignore_index=True)
df_dict[fname] = df_sorted
outname = fname.replace('.txt', '_sorted.txt')
df_sorted['text'].to_csv(outname, index=False, header=False, encoding='utf-8')
print(f"已處理:{fname} → 共{len(df_sorted)}筆,已輸出:{outname}")
Step4:壓縮並下載整理後的txt。
# 4. 壓縮並下載整理後的txt
import zipfile
import os
zipname = "sorted_txt_files.zip"
with zipfile.ZipFile(zipname, 'w') as zipf:
for fname in filenames:
outname = fname.replace('.txt', '_sorted.txt')
if os.path.exists(outname):
zipf.write(outname)
from google.colab import files
files.download(zipname)
Step5:跨檔案合併統計資訊。
# 5. 跨檔案合併統計資訊
import pandas as pd
# 合併所有檔案的已分類中文內容
all_chinese = []
for fname, df in df_dict.items():
all_chinese += df[df['分類']=='中文']['text'].tolist()
chinese_series = pd.Series(all_chinese)
freq = chinese_series.value_counts().sort_values(ascending=False)
print("\n=== 所有檔案合併後高頻率出現的文字可能是圖框資訊(每張都有) ===")
print(freq)
Step6:跨檔案合併統計清單下載。
# 6. 跨檔案合併統計清單下載
freq.to_csv('all_files_chinese_freq.txt', encoding='utf-8')
from google.colab import files
files.download('all_files_chinese_freq.txt')
從上一節統計清單中,透過資料的觀察(如圖),主要可以歸納分析為以下兩類:
圖13.3 字形相近誤判示例
1. 字形相近誤判:
例如指鋁窗的「铭窗(46次)與銘窗(11次)、铝窗(15次)」、指1/2B磚的「1/2B 碑(8次)」…等簡繁體混用情形,這可能來自原圖不同區域字體混雜的關係。
2. 專有名詞拆分或不統一:
如「技能定中心」(7次)、「建築製圖應用-電繪丙級技術士技能定」(3次)、「建製圖應用-電繪頂丙級技術士技能定」(2次);「建樂」(1次)、「建藥線」(4次)、「建線」(1次)等「建築線」的不同辨識結果…
今天透過資料的解析與標的物類別的反思,讓我們對於結構化資訊有了初步方向。下一篇,我們將繼續探討並實作,如何轉為有意義、可用的結構化數據,我們明天見!


 iThome鐵人賽
iThome鐵人賽